
Whether it’s Netflix predicting your next binge-watch, Spotify curate-crafting your Discover Weekly, or Amazon suggesting that extra item for your cart, recommendation systems run the modern web.
But how do these algorithms actually think?
In this post, we’ll break down the core paradigms of modern recommendation engines and build a fully functional Two-Tower retrieval model using TensorFlow Recommenders (TFRS) step by step.
🗺️ The Taxonomy of Recommendation Systems
Recommendation techniques generally fall into three classic buckets, each solving a different angle of the user-item matching puzzle.
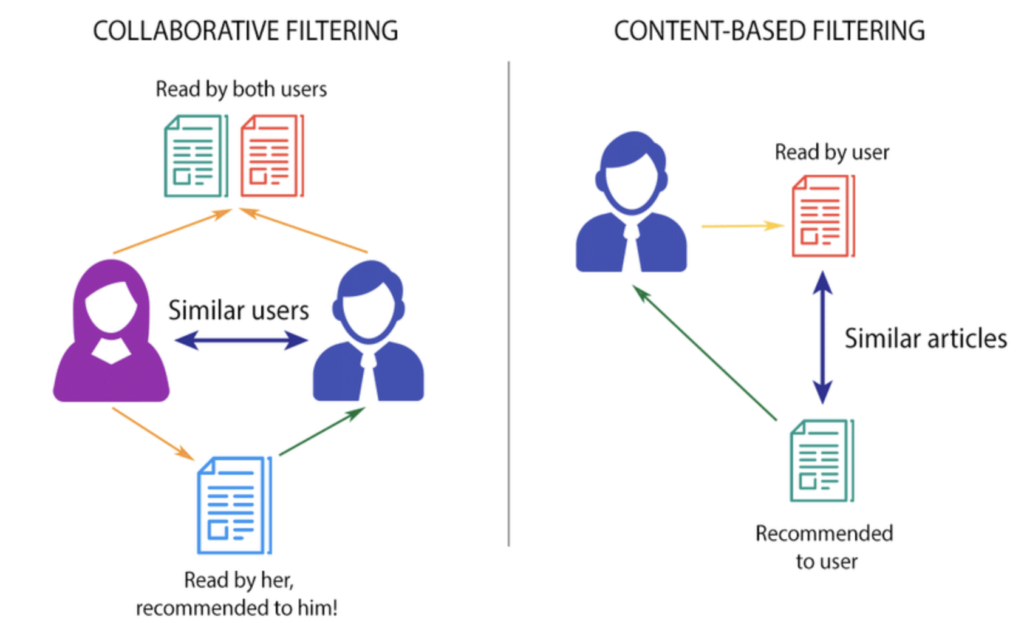
1. Content-Based Filtering
This technique recommends items similar to those a user liked in the past. It focuses entirely on the features of the items and the user profile.
- How it works: If you watch three sci-fi movies starring Keanu Reeves, the system finds other sci-fi movies starring Keanu Reeves.
- Pros: Doesn’t need data from other users; avoids the “cold-start problem” for new items.
- Cons: Tends to create an echo chamber (serendipity is low)—it rarely introduces users to completely new genres.
2. Collaborative Filtering
Collaborative filtering ignores item features entirely and relies on shared user behaviors.
- How it works: If User A and User B have a nearly identical watch history, and User A suddenly watches and loves Interstellar, the system will immediately recommend Interstellar to User B.
- Pros: Highly accurate and capable of discovering unexpected user interests.
- Cons: Suffers severely from the Cold-Start Problem—if a new user or a new item joins the platform with zero interaction history, the algorithm breaks down.
3. Hybrid Systems
To bypass the limitations of both, production systems (like Netflix) combine them. Hybrid systems blend collaborative interaction graphs with metadata features (tags, text descriptions, demographics) to achieve robust, well-rounded recommendations.
🏗️ The Production Standard: The Two-Tower Architecture
When recommending across millions of items in milliseconds, checking every single item pair is computationally impossible. Production systems use a two-stage approach: Retrieval (filtering millions down to hundreds) and Ranking (scoring the top hundreds carefully).
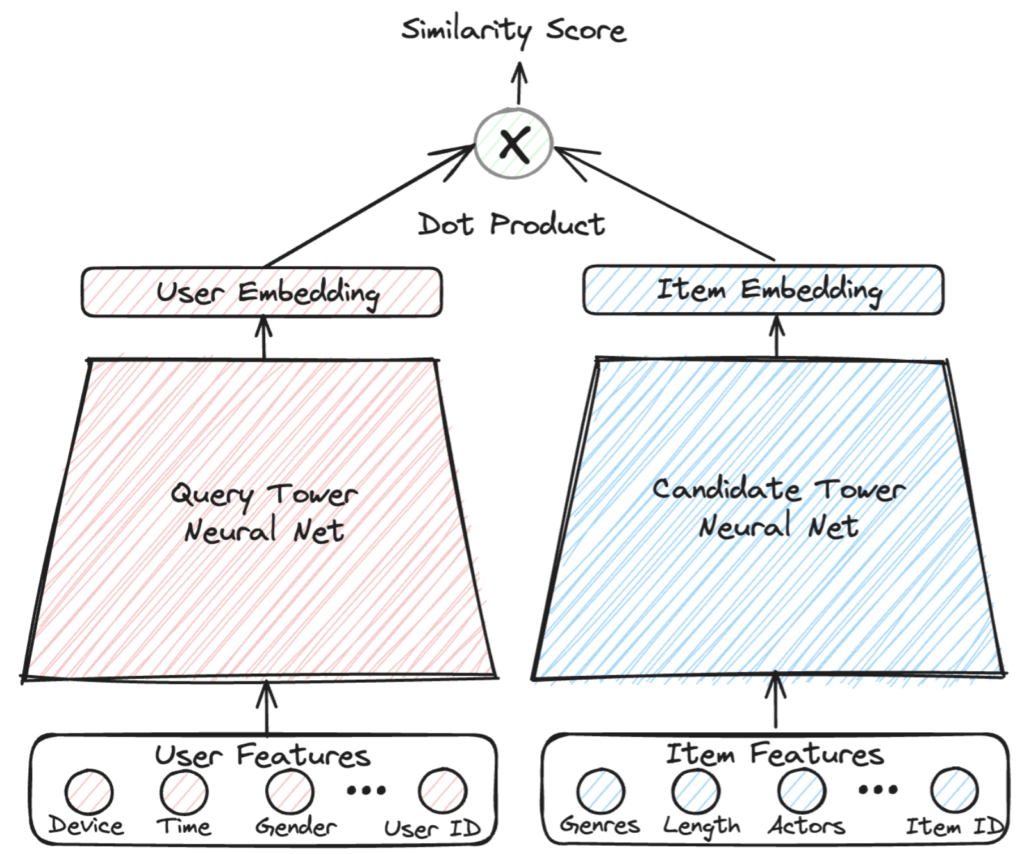
For the retrieval phase, the industry standard is the Two-Tower Model:
- The Query Tower: Learns a low-dimensional embedding space for the user/context.
- The Candidate Tower: Learns a matching embedding space for the items (movies, products, articles).
- The Objective: Maximize the dot product (mathematical similarity) between the user embedding and the item embedding for successful interactions.
🛠️ Step-by-Step Implementation with TensorFlow Recommenders
Let’s build a clean Two-Tower retrieval model using tensorflow-recommenders. We’ll use the classic MovieLens 100k dataset to teach our system to recommend movies to users.
Step 1: Install Dependencies
Open your terminal and install the required TensorFlow packages:
Bash
pip install tensorflow tensorflow-recommenders tensorflow-datasets
Step 2: Import Packages & Load Datasets
We start by importing the libraries and loading the MovieLens dataset via TensorFlow Datasets (TFDS). We separate the dataset into historical ratings (user-movie interactions) and the raw pool of all available movies.
Python
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
from typing import Dict, Text
# Load MovieLens 100k data
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
# Map features to extract only what we need
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
})
movies = movies.map(lambda x: x["movie_title"])
Step 3: Build Vocabulary Lookups
Neural networks don’t understand raw strings. We need to create an index mapping every unique User ID and Movie Title to an integer, which will later feed into our embedding layers.
Python
# Create lookup vocabularies for IDs and Titles
user_ids_vocabulary = tf.keras.layers.StringLookup(mask_token=None)
user_ids_vocabulary.adapt(ratings.map(lambda x: x["user_id"]))
movie_titles_vocabulary = tf.keras.layers.StringLookup(mask_token=None)
movie_titles_vocabulary.adapt(movies)
Step 4: Define the Two-Tower Model Architecture
Now we inherit from tfrs.Model and build our two towers. We define the Query Tower (for users) and the Candidate Tower (for movies). We also define our retrieval task to calculate the mathematical similarity between their outputs.
Python
class MovieLensModel(tfrs.Model):
def __init__(self):
super().__init__()
embedding_dimension = 32
# --- The Query Tower (User Representation) ---
self.user_model = tf.keras.Sequential([
user_ids_vocabulary,
tf.keras.layers.Embedding(user_ids_vocabulary.vocabulary_size(), embedding_dimension)
])
# --- The Candidate Tower (Movie Representation) ---
self.movie_model = tf.keras.Sequential([
movie_titles_vocabulary,
tf.keras.layers.Embedding(movie_titles_vocabulary.vocabulary_size(), embedding_dimension)
])
# --- The Evaluation Metrics & Task ---
metrics = tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.movie_model)
)
self.task = tfrs.tasks.Retrieval(metrics=metrics)
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
# Pass features through respective towers
user_embeddings = self.user_model(features["user_id"])
movie_embeddings = self.movie_model(features["movie_title"])
# Compute the loss based on similarity matching
return self.task(user_embeddings, movie_embeddings)
Step 5: Compile and Train the Model
With the model architecture set, we instantiate it, select an optimizer (Adagrad is standard for recommendation models), shuffle our dataset, and kick off training.
Python
# Instantiate and compile
model = MovieLensModel()
model.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate=0.1))
# Batch and cache the training data for speed
cached_train = ratings.shuffle(100_000).batch(8192).cache()
# Train for 5 epochs
print("🚀 Starting Two-Tower Model training...")
model.fit(cached_train, epochs=5)
print("✅ Training complete!")
Step 6: Create the Recommendation Index & Predict
Once trained, we don’t want to calculate distances manually. TFRS offers a BruteForce layer that takes a User ID, passes it through the Query Tower, scans the Candidate Tower database, and instantly spits out the top matches.
Python
# Build a fast retrieval index
index = tfrs.layers.factorized_top_k.BruteForce(model.user_model)
index.index_from_dataset(
tf.data.Dataset.zip((movies.batch(100), movies.batch(100).map(model.movie_model)))
)
# Request recommendations for User "42"
_, titles = index(tf.constant(["42"]))
print(f"Top 3 recommendations for User 42: {[title.decode('utf-8') for title in titles[0, :3].numpy()]}")
📊 Next Steps for Production Performance
If you want to move beyond basic retrieval, focus on these architecture improvements:
- Include Contextual Features: Modify the Query Tower to ingest not just user IDs, but user location, time of day, device type, or historical interaction lists.
- Transition to Approximate Nearest Neighbors (ANN): Brute-force scanning becomes too slow as your catalogue scales. Use indexing tools like ScaNN or Faiss inside your retrieval layer to surface items in sub-millisecond timelines.
- Add a Ranking Tower: Follow your retrieval layer with a deep neural network that optimizes for exact click-through rates (CTR) or watch-time weightings.